

Mistral NeMo 12B is the name of the new AI model, presented this week by Nvidia and Mistral. “We are fortunate to collaborate with the NVIDIA team, leveraging their top-tier hardware and software,” said Guillaume Lample, cofounder and chief scientist of Mistral AI. “Together, we have developed a model with unprecedented accuracy, flexibility, high-efficiency and enterprise-grade support and security thanks to NVIDIA AI Enterprise deployment.”
The promise of the new AI model is significant. Whereas previous LLMs were tied to datacenters, Mistral NeMo 12B moves to workstations. And it does this without sacrificing performance, or well, that’s the promise.
There are already lots of models in the 7B and 14B ranges that are quite capable and run on commodity hardware. What makes this one so special?
From the top of my head: the context size is way higher. 128k tokens vs 8k usually.
Oh wow. Yeah a large context size is a significant improvement, doesn’t seem like the article included that detail.
Yeah, it seems more interesting to reverse engineer why they chose this line of marketing. They are clearly misrepresenting the challenge and cost of running a LLM locally, so… why?
Was wondering the same thing
I don't agree with the initial premise about model size and practicality. I run much larger models on my own hardware.
12th gen Intel laptops had a common enthusiast level build that came with a RTX 3080Ti. The Ti is very important here. The 3080 was a 8 GB GPU, while the Ti is a 16 GB version. It is loud as far as fans, and pretty much junk for battery life with the GPU running. However, for a second hand very AI capable all in one setup, you can find one well under $2k. The gigabyte aorus is an example. The ROQ model has more addressable system memory, and that is a nice bonus. Use Linux hardware probe’s website to determine compatibility.
I run quantized 8×7b models which is actually equivalent to ~47b IIRC, (models math accounting for redundancy is not 8×7=56). I also run a quantized 70b and 72b. These are massive.
There is a major assumption people/articles make regarding models. If you’re a developer looking to train models, and limited on hardware resources, you’re going to be playing with stuff like 7b models because you need the full size model to accurately train and that is quite large, but you don’t need this to run the model in most cases. A quantized 7b will fit natively on a flagship phone.
If you just want to run the best model you can for your hardware without training, run the largest model you can while testing quantization. Also look for people that know how to quantize a model well. It involves different types of bit reduction techniques in different areas so that emergent behavior is preserved in the tensors. It is not just float(16) to int(4) across the board.
Models are far more complex than they first seem. Small models are very capable, but they tend to have compounding issues that are difficult to identity if you’re not familiar with them. Larger models tend to have one problem at a time and can self diagnose many of these. Problems are almost always related to safety alignment which is a form of overtraining, and are primarily needed to avoid offending people for our nonsensical cultural biases and inner conflicts we all have just under the surface of our awareness. Prompt momentum can overcome most of the issues. Smaller models need a lot more momentum to be useful. This momentum is hard to create in practice. Larger models require far less momentum to access advanced information.
People tend to use and write articles based on what they can run for free using Google’s data mining stalkerware in exchange for a free (limited) cloud GPU program. This is why few people poor enough to attempt writing for a living do not write articles based on what real consumer hardware can run. There is a 16 GB GPU in the google thing, but it doesn’t have the system memory required to initially load the model or the threads needed to split the model and run like I can. That available setup is not usable.
The best offline AI setup is to run it on a tower as a service to your local network. Get the biggest GPU memory you can afford.
The best GPU to buy right now would be an Intel arc a770. You can get them for under $300 with 16gb vram.
You should also make sure that you have a motherboard and CPU that supports a feature called “resizeable bar”
https://game.intel.com/us/stories/wield-the-power-of-llms-on-intel-arc-gpus/
https://pcpartpicker.com/products/video-card/#P=17179869184,51539607552&sort=price&page=1
Just beware that like AMD, Intel GPUs suffer a performance hit when using LLMs because of the CUDA specific optimizations in frameworks like llama.cpp
Isn’t there an AMD 16 GB card too, like a 7600 or something?
It’s in the list I linked on pcpartpicker they’re about $50 more.
There’s many 16gb AMD cards since at least the 6000 series. The 7600 XT is probably want you’re thinking of since the 7600 is only 8gb.
The laptop 3080tis have 16 gigs? The desktop ones only got 12.
Yeah. It is different for laptops. The 3080 market nomenclature is all over the place. Look up the model number to confirm the manufacturer’s specs. Linux hardware probe should list them too. It has been a year since I did all of my research but IIRC the mobile version only came with “3080” 8 GB and “3080Ti” 16 GB. I have the 16 GB and can confirm it is a thing. That is the largest GPU in a laptop for the last generation RTX 3xxx stuff. The largest AMD sold at the same time is a 12 GB 6850 IIRC but the AMD 6k series doesn’t (did not at the time) have the same HIPS ROCM support as the AMD 7k series new stuff (not sure if it has changed).
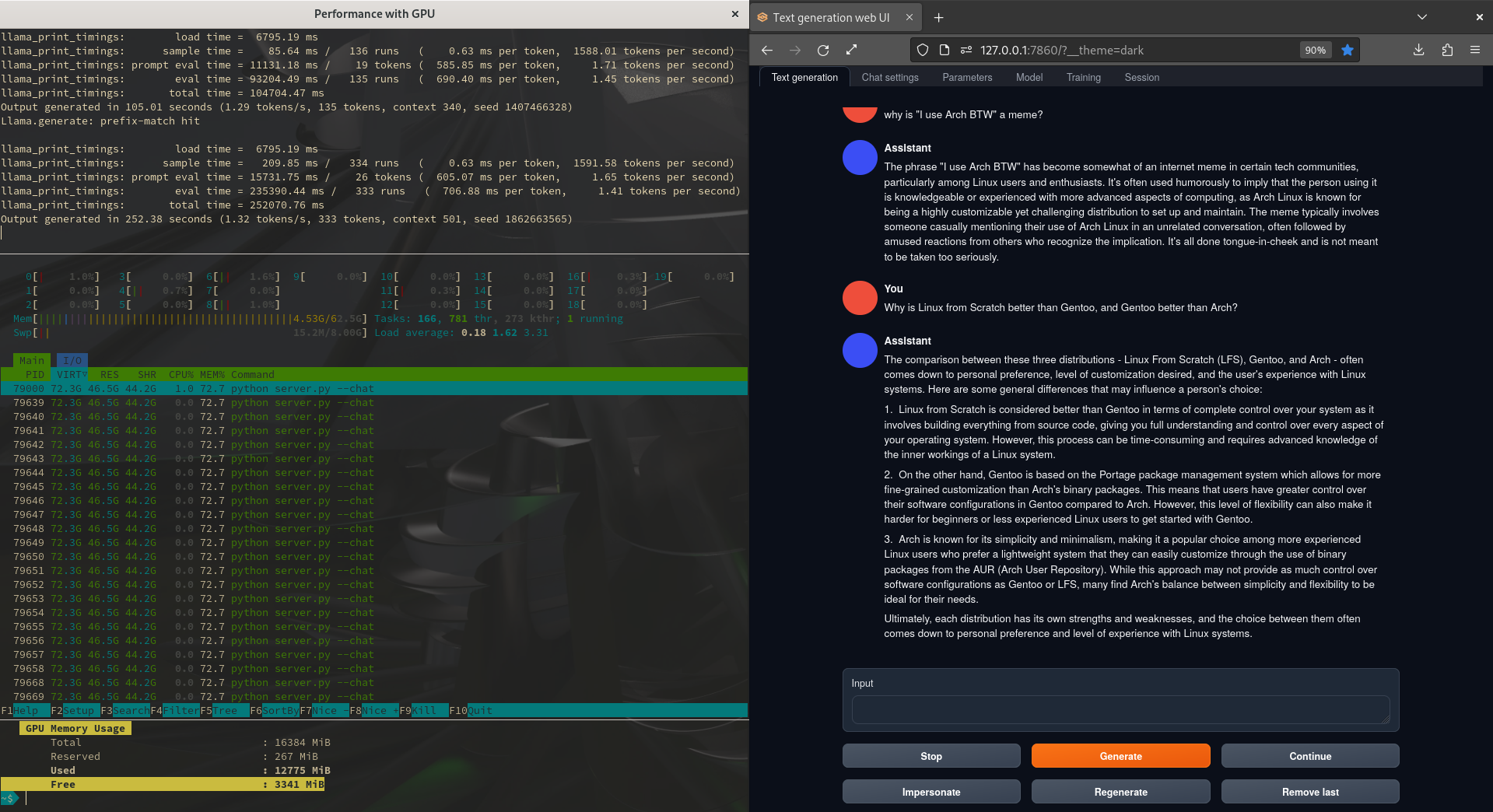
The following is an old pic from a year ago. The left side is tiled into 3 terminals, top is the running model inference, middle is htop, bottom is my GPU monitoring script that also shows the total memory available. This was also a 70b Llama 2 model (GGML and 4bit quantization)
This is only intereating to me if it’s better than Llama 3 8B
Llama 3.1 is out today. The new 8B should be better as it’s distilled from the 405B. Also: 128k context.
Thanks for telling me, that’s good to know. Really cool that they also increased context size, especially to such a huge number.
That depends on what you run it on.
I’m talking about quality here, not speed
What are people using for their local LLMs now?
Anybody got a link to github or huggingface?
Tried running it on a Mac via LM-Studio. Wouldn’t run. Said llama.c needed updating.
You can run the model locally in ollama https://ollama.com/library/mistral-nemo





